Runtime Concepts
[This page is being used to collaborate on a paper. You are welcome to read and comment on it, but consider it a work in progress, not a final product.]
Title: Runtime Concepts: Generic Programming and Runtime Polymorphism
Authors: Sean Parent, Mat Marcus, Peter Pirkelbauer
Contents
- Abstract
- Introduction
- Body
- Performance Experiments
- Related Work
- Summary And Future Work
- Acknowledgments
- Bibliography
- Appendix
Abstract
A key premise of Generic Programming is that algorithms can be expressed in terms of concepts and then applied to any model that satisfies these concepts. In C++, the application of Generic Programming has been largely limited to algorithms operating on collections which are statically and homogeneously typed, while Object Oriented Programming has been used where runtime polymorphism is required.
A definition of runtime polymorphism in Generic Programming terms is presented along with techniques for efficiently implementing runtime polymorphism. The implementation techniques allow for existing STL algorithms to be used effectively with heterogeneous collections of types, further decoupling types from algorithms allowing for greater code reuse.
Introduction
General overview of development in GP: since LISP in 60ies [?] (?); popularized in 80ies and 90ies - STL implementation [MS88]. functional language approach [?]; unification of GP [DRJ05]; ConceptC++ [GJS+06].
Generic programming offers a number of abstraction benefits compared to other programming paradigms.
Generic programming fosters regularity and value-semantics. Regularity
essentially describes the semantics of built-in types and requires operations
for construction, copy-construction, destruction, assignment,
equality-comparison, and for a stricter definition also ordering. Built-in type
semantics is value-based and therefore regular semantics is inherently distinct
from reference semantics. Regularity together with value-semantics eases
reasoning about programs and allows the programmer to perform optimizations
[DS98]. We extend the regular operations defined by [DS98] and add efficient
operations for swap and move. Each regular object is swapable by std::swap
which relies on copy construction and assignment. The explicit swap operation
allows avoiding the creation of temporary objects. Likewise, the addition of
move allows the reuse of part objects that are about to be destructed.
[ Shape example ]
Regular semantics particularly simplifies memory management because the lifetime of any value ends whenever its name goes out of scope or the lifetime of its container ends. Furthermore, the C++ language requires the compiler to manage the lifetime of temporary values. Consider the following loop:
template <typename T>
void saxpy(T[] x, T[] y, T a, size_t dim)
{
for (int i = 0; i < dim; i++) {
y[i] = a * x[i] + y[i];
}
}
Both functions * and + create temporary values, which are used as input for subsequent function calls (+ and = respectively), and automatically deallocated as soon as the full expression has been evaluated [C++ Standard Draft 2003]. Using reference/pointer semantics for type T instead would obviate those memory management facilities and either require some automatic memory reclamation scheme or put the burden of releasing memory on the programmer.
Generic programming is concerned with providing algorithms and data structures on an abstract level without compromising efficiency. Hence, some algorithms can have several implementations that differ in their concept requirements and efficiency. Since stricter concept requirements improve efficiency, selection of the best algorithm is concept-based. The current STL implementation distinguishes concepts using associated types and relies on the C++ overload resolution mechanism to select the optimal algorithm. Therefore, the selected algorithm is multi-variant in respect to its parameter types.
Generic programming does not make the relationship between concept and types tangible in the code. This weak relationship allows the programmer to focus on the desired behavior of the class without restrictions from prematurely defined interfaces. This typically results in shallow or no hierarchies, which do not disperse implementation across a number of classes. For example, the Adobe Source Libraries uses inheritance only for X classes. Should a class not meet the requirements of a concept, models can be used to shape its behavior.
Using generic programming allows to cleanly separate data structures from algorithms. This is achieved by stepwise abstraction from concrete and efficient algorithms to a more general but equally efficient implementation. For example, the C++ STL [?] introduces iterators, an abstraction for a position within a sequence, as base for algorithms operating on sequential data structures.
The current C++ standard supports generic programming through function overloading and the template mechanism. While templates allow type-based parameterizations of algorithms and classes, the support for concept definition and - checking is limited. Recent research in this area provides first class concept integration and also improves separate compilation [GJS+06]. By mandating distinct instantiations for distinct parameter tuples, C++ ensures optimal performance but simultaneously hampers template use across DLL boundaries and data structures meant to store a heterogeneous set of data.
Motivation
Many software projects require working on heterogeneous collections of data. Typically, this polymorphism is expressed through inheritance. However, inheritance tightly couples a type with a set of operations which can be performed on it. This tight coupling is often manifest through implicit data structures and algorithms which hinder the ability to understand and reuse code. Because the polymorphic types can be of different sizes they must be allocated in the free store, this introduces the use of object factories, adds an additional level of indirection, and imposes a need to manage the free store memory. This in terms leads to the use of reference counted pointers and the requirement of controlling multiple references to objects in a threaded environment which negatively impact performance.
Outline
Body
Definition of Generic Programming
“By generic programming, we mean the definition of algorithms and data structures at an abstract or generic level, thereby accomplishing many related programming tasks simultaneously” [MS88].
The ideal for generic programming is to represent code at the highest level of abstraction without loss of efficiency in both actual execution speed and resource usage compared to the best code written through any other means. The general process to achieve this is known as “lifting”, a process of abstraction where the types used within a concrete algorithm are replaced by the semantic properties of those types necessary for the algorithm to perform.
Semantic Requirement
In the process of abstraction the tight binding from an algorithm to concrete types is relaxed and replaced with a set of semantic requirements. Types must satisfy these requirements in order to work properly with a generic algorithm. Checking types against arbitrary semantic requirements is in general undecidable. Thus, semantic requirements are stated in tables, in documentation, and may at times be asserted within the code. Some systems [? Alloy Model Checker] allow to formally describe semantic requirements, but none of those is part of current C++. [note: we could also mention axioms of the concept proposal]. Instead, the compiler checks for the presence of syntactic constructs, which are a part of semantic requirements. Consider the following example, which describes the requirement that equality holds after a value x is copy constructed from another value y of the same type T. The compiler will check any type for the presence of the copy constructor and equality operator.
template <class T>
concept CopyEquality
{
void foo(T x)
{
T y(x);
assert(x == y);
}
}
Concept
Dealing with individual semantic requirements would be cumbersome in practice. However, it is observed that sets of consistent requirements cluster into natural groups which are known as “concepts”. As an example, even the trivial requirement for copy given above relies on an equality comparison. The notion of copy and equality are very tightly coupled. Although any collection of requirements may define a concept, only concepts which enable new classes of algorithms are interesting. It is also important to distinguish between the syntactic and semantic requirements of concepts. As an example, an algorithm may require that a type be copyable, which is part of the concept known as “Regular”
- although the algorithm does not require that the types be equality comparable, we would say that it’s defined for regular types because even if the type doesn’t implement equality comparison, the result of copying must be equivalent objects. Such a type is said to be pseudo regular.
Model
Neither is it desireable nor possible to forsee all algorithms and their concept requirements with which a type would be used. Consequently, models are introduced as decoupling mechanism allowing clean separation of concrete types from concepts. The designer of a class should be able to focus on providing the correct semantics without distraction from potential requirements, some of which he might not even know. When the type is used in context of an algorithm a model shapes its interface and behaviour to meet the concept requirements.
Algorithm
“The central notion is that of generic algorithms, which are parameterized procedural schemata that are completely independent of the underlying data representation and are derived from concrete, efficient algorithms” [MS88].
Concept Refinement
A concept \(C_r\) augmenting another concept \(C_0\) with additional requirements is a concept refinement and denoted by \(C_r\) pred \(C_0\). Therefore the number of types meeting the semantic requirements for \(C_r\) is smaller or equal compared to the number of types that meet the requirements of \(C_0\). In turn, extending the semantic requirements increases the number of algorithms that can be expressed with a given concept. For example, RandomAccess-Iterator refines Bidirectional-Iterator and adds the requirement for constant time random access ([]-operator), which allows writing a binary search algorithm.
Algorithm Refinement
Parallel to concept refinements, an algorithms \(A_0\) can be refined by another algorithm \(A_r\) to exploit the stronger concept requirements and achieve better space- and/or runtime- efficiency. For example, the complexity of reverse on Bidirectional-Iterator is O(n), while it is O(lg n) for Forward-Iterator (assuming less than O(n) memory usage).
Analogy to Algebraic Structures
We emphasize the analogy of our view of generic programming with algebraic structures. At the core of algebraic structures is a set of axioms and derivation rules on which base useful theorems can be expressed. Concrete Models map undefined terms onto real systems. The more independent axioms a systems has the more theorems can be expressed, but the fewer concrete models exist, which are consistent with the axioms. The following table makes the relationship of generic programming with algebra explicit.
| Generic Programming | Algebra |
|---|---|
| Semantic Requirement | Axiom |
| Concept | Algebraic Structure |
| Model | Model |
| Algorithms | Theorems |
| Function | Function |
Generic Polymorphism
[This section is intended to introduce runtime-polymorphism based on concepts and to show that a concept based definition of runtime polymorphism is a super set of the C++ inheritance model of polymorphism.]
In the presented work, we replace a concrete type with a placeholder-type called runtime-concept when instantiating STL-containers. Analogue to the compile-time definition, we define a runtime-concept as a number of runtime-models, which satisfy a common set of requirements. Although the containers are type checked based on the runtime-concept, they can store any object whose type models that runtime-concept. Unlike the generic programming paradigm, our implementation expresses the relationship between a runtime-concept and its models inside the C++ type system using inheritance.
Representing the concept-model relationship based on OOP polymorphism is not a novel idea and languages such as Eiffel [?], Java [?], and C# [?] implement that technique. Conversely, the C++ language designers have repeatedly explored and rejected to adopt this base-/derived- class scheme for compile time concept checking. The identified problems include intrusiveness, rigid signatures, type proliferation, and performance issues [Str03].
Instead of requiring an explicit relationship between runtime-concept and concrete type we apply the external polymorphism pattern (EPP) [CSH96]. Therefore, a runtime-model \(M\) is a template class that gets instantiated with a concrete type \(T\). Its instantiation is orthogonal to the definition of concrete types. A programmer can specialize the model-template for a particular type in order to provide adjustments to the interface if needed.
The use of polymorphic objects is non regular and thus problematic. As a matter of fact, polymorphic classes alone cannot be regular but neither can regular classes alone be polymorphic. Consider a class hierarchy with two classes \(Base, Derived\) and copy semantics. Writing the code in terms of copy construction would encode the type in the code, but even using a clone function as illustrated in Fig. <?b> would not work, as the returned object of Derived::clone would be subject to slicing. Conversely, returning an object by reference, would compromise value semantics and regularity Fig<?a>.
// (a) Non-polymorphic regularity Base Base::clone(); Derived Derived::clone(); // (b) Non-regular polymorphism Base& Base::clone(); Derived& Derived::clone();
Our solution to this problem is a combination of both. We represent runtime-concepts through a regular (\(R_0\)) and polymorphic layer (\(P0\)). The layers of the generic polymorphism pattern are shown in figure <1>. The regular-object leverages its polymorphic pendants and provides a regular interface for them. \(R_0\) is a concrete class referring to some object that implement the interface ConceptInterface. Thus \(R_0\) can be regarded as a placeholder type for template instantiations. \(P_0\) is an abstract class defining the operations on the objects. The model \(M_0\) is inherits from \(P_0\) and is templatized with a concrete type \(T\). Its instantiation \(M_0(T)\) maps the operations defined in \(P_0\) onto operations of \(T\).
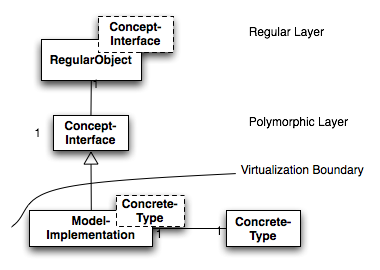
figure: Class Colaboration Figure 1
Table <?> gives an overview how elements of concept definitions are represented within the regular and polymorphic layer.
| Regular Type | Regular Layer (R) | Polymorphic Layer (P) |
|---|---|---|
| Default Constructor | R a | - |
| Copy Constructor | R(const R&) | virtual P& clone() |
| Destructor | ~R() | virtual ~P() |
| Assignment | R& operator=(R&, const R&) | virtual void assign(const P&) |
| Equality | bool operator==(const R&, const R&) | virtual bool equal(const P&) const |
| Swap | swap(R&) | - |
| Move | move(R&) | - |
We describe how elements of compile time concepts are mapped in the regular and polymorphic layer and present an example by means of the regularity concept.
Functions (Operators, Constructors, etc): In the regular layer, any signature or use case pattern requirement can be directly represented by member- or free-standing functions. These functions typically forward calls to the polymorphic layer, where these functions are realized as member functions. Notably, swap and move operations are exceptions to these rule and can be implemented more efficiently by swapping (or moving) the pointer to the polymorphic part.
Data Members: Consider the following concept member_x written in usage pattern style:
template <typename C>
concept member_x
{
C c;
c.x = 1;
}
The concept requires the presence of a data member x, where x has an assignment operator that allows an integer argument. Since the runtime-concept model is non-intrusive and the concept C does not enforce a particular type for x, data members cannot be directly represented. Instead, we use property objects, which sole purpose is to virtualize member access and invoke the appropriate functions in the polymorphic layer. An example for a property object in the regular layer is given by the next code fragment.
struct runtime_concept_member_x
{
struct x_property
{ void operator=(int);
};
x_property x;
};
The runtime-concept definition for data members of user defined types can be derived by applying the modeling rules recursively.
Associated Types: In the regular layer, associated types are directly represented and identify another regular layer type in the case runtime polymorphism is needed. Then, the polymorphic object-parts are constructed by factory methods [GoF?] which create objects of different dynamic types.
Concept Refinements: In the generic polymorphism model, concept refinements \(C_r <: C_0\) are represented by regular \(R_0, R_r\) and polymorphic classes \(P_0, P_r\). \(R_0\) and \(R_r\) model the concepts \(C_0\) and \(C_r\) respectively. A subclass relationship \(R_r subclass R_0\) is possible but not required. \(P_0\) and \(P_r\) are the polymorphic counterparts of \(R_0\) and \(R_r\) respectively. The requirement that \(P_r subtype P_0\) allows the use of models \(M_r\) wherever \(M_0\) is expected (i.e.: together with \(R_0\)).
Given our definition for Generic Programming, we can define runtime-polymorphism for Generic Programming to be a property of algorithms which operate on a collection of models where the types in the model are either partially or fully determined at runtime.
Relationship To Object Oriented Programming
figure: Class Colaboration Figure 1
In Object Oriented Programming the notion of inheritance is used to model an “is-a” relationship. The base class(s) provides a syntactic template for modeling a concept where the derived classes must provide the implementation satisfying the semantic requirements for the interface. Normally, type variance is only allowed for a single type (the type which is derived) and not from any affiliated types. Likewise, operations may only be type variant on the first parameter.
Degrees of Runtime Variability
In this paper we have developed our notion of polymorphism in generic programming and presented an implementation. We can classify alternative designs for heterogeneous containers according to the runtime variability they permit.
Static
The elements of a container are statically and homogeneously typed. This model is directly supported by C++ and results in very efficient machine code but is inflexible in respect to types of objects. If heterogeneous containers are needed, programmers typically turn to object oriented polymorphism and store pointers to objects.
Variant
In many applications, the set of types stored in a container is known at compile-time. In these cases a variant type that is the set-union of all potential data types suffices to implement the desired behavior. Hence, variant types, such as the Boost.Variant are similar to discriminated unions but overcome their limitation in regards to storing non POD types. A priori information of all involved types enables to determine the size of the variant at compile time, thus eliminating the need for a two layer architecture. In addition, the compiler can fully type check code against the types inside the variant. The downside of this approach is the definition of assignment-semantics, when the types stored in the left-hand and right-hand object differ. Consider the following assignment:
x = y
Since, the actual type of x differs from y, its element has to be destructed before the assignment can be carried out. However, when the copy construction fails x is left in an undefined state. A detailed discussion of this problem and its potential solutions is given by Boost:”Never-Empty” Guarantee
Open
Some application require to store also data-types, for example defined in DLLs, that are not statically known at compile- and link-time. Implementations, like the presented one, which do not impose such restrictions are called open. Other existing designs include Boost.Any and [Dig05]. The boost implementation is similar to ours insofar as it uses the virtual functions mechanism and EPP to achieve polymorphism. The operations supported include copy-construction, assignment, destruction, safe-, and unsafe cast operations. Instead of having the polymorphic object allocated separately [Dig05] integrates them into one layer. Only, if the polymorphic part exceed some size it will be stored apart. Instead of virtual functions each object has a static function table. Due to memory locality, reduced heap allocations, and the low level implementation [Dig05] yields superior performance. However, the reuse of memory leads to similar problems described for the variant alternative. In contrast to our approach both implementations do not allow to customize the user interface.
Open Variant
Open-variance is a hybrid of the variant and open techniques. To achieve better performance some types are directly represented in the variant. Other types, which are either unknown at compile time, occur rarely, or are too large, can be represented by one of the open techniques.
Just-In-Time Virtualizing (Type Erasure)
Polymorphism Parameterized By Concept
Runtime Types
Refinement and Dispatching
Since the polymorphic layer (e.g.: \(P_r\)) could model a more refined concept than the regular layer it is bound too (e.g.: \(R_0\)), dispatching based on the concept implemented by the regular layer can lead to suboptimal results. Consider a random access container attached to a regular layer modeling a sequence. The complexity for lower_bound would be O(n) compared to O(lg n) if only the regular layer were considered. The runtime could improve even more if the operations of the concrete container \(T\) were invoked, instead of the virtual functions defined in the polymorphic layer.
Our solution to this problem replaces the algorithm instantiation and calls a dispatch mechanism instead. Based on the dynamic type of the model the dispatch mechanism invokes the most suitable function from a family. The function family is comprised of instantiation(s) of an algorithm family \(A_0, A_r\) with either the concrete type \(T\), or one of the regular classes \(R_0, R_r\). The dispatch mechanism guarantees the presence of algorithms that operate on \(R_0\). It is the responsibility of the programmer to add more efficient algorithms to the library.
The dispatch mechanism relies on the following propositions:
- \(P_0\) inherits \(P_r\)
- \(P_r\) inherits \(M_r\) and therefore \(P_0\) inherits … inherits \(P_r\) inherits \(M_r\).
- \(foreach T\) there is only one model \(M_t\) within an inheritance graph rooted in \(P_0\).
Based on the first two propositions, the dispatcher walks the inheritance chain from the model \(M_r(T)\) over polymorphic representations of refined concepts \(P_r\) to the base class \(P_0\). The third proposition guarantees that any mapping between an algorithm instantiated with a concrete type \(A(T)\) and a model \(M(T)\) is bijective within a concept family. When the dispatcher finds an algorithm, it is typically a stub that either further unwraps the model \(M_r(T) -> T\) or rewraps the polymorphic concept in the appropriate regular layer \(P_r -> R_r\) before the call of the actual algorithm.
Performance Experiments
Open-Closed
Generic vs Generic-polymorphic
Related Work
[KLS04], [IN06]
Summary And Future Work
Runtime Type Functions
Runtime Type References
Acknowledgments
Bibliography
[DRJ05] Dos Reis, Gabriel; Järvi, Jaako: What is Generic Programming? LCSD’05.
[GJS+06] Gregor, Douglas; Järvi, Jaako; Siek, Jeremy; Stroustrup, Bjarne; Dos Reis, Gabriel; Lumsdaine, Andrew: Concepts: linguistic support for generic programming in C++ . OOPSLA’06.
[MS88] Musser, David R.; Stepanov, Alexander A.: Generic Programming. ISSAC ‘88.
[Vel00] Veldhuizen, Todd: Five compilation models for C++ templates. TMPW ‘00.
[Str03] Stroustrup, Bjarne: Concept checking - a more abstract way to type checking. C++ Committee, Paper 1510, 2003.
[CSH96] Cleeland, C.; Schmidt, D.; Harrison, T.: External Polymorphism PLoPD ‘96.
[DS98] James C. Dehnert and Alexander Stepanov. Fundamentals of Generic Programming. In Report of the Dagstuhl Seminar on Generic Programming, volume 1766 of Lecture Notes in Computer Science, pages 1–11, Schloss Dagstuhl, Germany, April 1998.
[IN06] Igarashi, Atsushi; Nagira, Hideshi: Union Types for ObjectOriented Programming SAC ‘06.
[KLS04] Kiselyov, Oleg; Lämmel, Ralf; Schupke, Keean: Strongly Typed Heterogeneous Collections, Haskell ‘04.
[Dig05] Diggins, Christopher: An Efficient Variant Type. CUJ 2005.
Appendix
The Proxy Dilemma
In C++ the concept of a reference to a type is tightly bound to the specific type generated by the T& type operation. At times it is desirable to construct a user defined type which acts as a form of reference to another type. We refer to this as a proxy type.
The standard template library tries to allow for arbitrary proxy types by including “reference” as one of the traits for an iterator but this is insufficient. The problem becomes apparent when we look at the implementation of swap:
template <typename T>
void swap(T& x, T& y)
{
T tmp(x);
x = y;
y = tmp;
}
If T is itself a proxy then this code will swap the two proxies, not the underlying values. Ideally what we would like is that the syntax T& would match “any type which is a reference to T” not generate a reference to the proxy type. This failure in type deduction leaves the copy construction of T ambiguous - in this case a copy of the value, not just the proxy, is desired. No actual harm occurs, however, until we assign through the reference.
The best that we are able to easily achieve is a proxy type which behaves as a reference when the referenced value is not mutable.
The original code for the C++ standard template library works, to a very limited extent, with proxies because few algorithms actually require full copy semantics (move is sufficient) and the code makes use of a function iter_swap() for swap operations which avoids the above problem with swap by using the iterators associated value type rather than trying to deduce the type from the proxy. However, the requirement for standard algorithms to be implemented in terms of iter_swap() was never stated and cannot be relied upon. The problem also isn’t limited to only swap operations, any calls which take the proxy by mutable reference will fail.
To test the ideas presented in this paper with the standard algorithms we used the following scheme:
- proxies maintain a reference count to the number of proxies to a value.
- when assigning through a proxy if the reference count is greater than one, then a copy of the value is made and all other proxies referring to the value are set to refer to the copy.
This relies on the fact that it would be inefficient to make a copy of a value and then assign over the top of it. This is a very fragile and costly solution but it was sufficient to test the ideas in this paper. Solving the proxy dilemma properly in C++ is an open problem.